ES查询和索引
倒排索引(Inverted Index)也叫反向索引,有反向索引必有正向索引、正排索引(doc values)。
正向索引是通过key找value,反向索引则是通过value找key。
全文搜索需要用倒排索引,而排序和聚合则需要使用正排索引。
创建索引(index)
我们在创建index的时候,也就是说创建es的表结构的时候,即通过 es http API 去创建 mappings 的时候,给每个字段(field)的属性定义里面,就设置了此字段是否可搜索、是否可聚合。
PUT /demo_index_mappings
{
"mappings": {
"properties": {
"tags": {
"type": "text",
"index": "true",
"doc_values": "true" // text类型不支持
}
}
}
}
倒排索引数据结构
比喻:一篇文章包含了哪些词,它从词出发,记载了这个词在哪些文档中出现过,由两部分组成:词典、倒排表
Term词典解释
Term(单词):一段文本经过分析器分析以后就会输出一串单词,这一个一个的就叫做Term(直译为:单词)
倒排索引采用 Immutable Design,一旦生成,不可更改。
不可变更的优点
1、无需考虑并发写文件的问题,避免了锁机制带来的性能问题
2、一旦读入内核的文件系统缓存,便留在那里。只要文件系统存有足够大的空间。大部分请求就会直接请求内存,不会命中磁盘,提升了很大的性能
不可变更的缺点
如果需要让一个新的文档可以被索引,需要重建整个索引。
FST的由来和设计
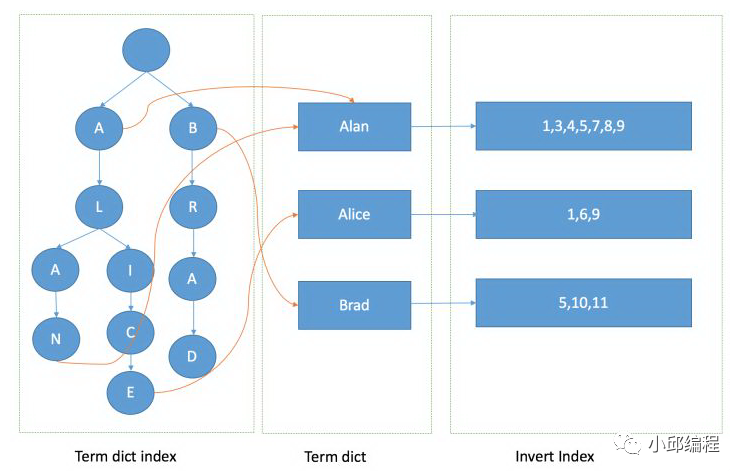
Term Dictionary(分词的词典) 很大,放内存不合适,也不是树形结构,没办法像B树/B+树那样部分换入内存,提高性能。
所以,Lucene单独为Term Dictionary创建了一个索引:Term Index。目的:用来记录以不同前缀开头的Term分别在Term Dictionary的起始位置。
最早设计思路
Term Index可以用HashMap来实现,当需要查找一个Term时,可以通过Hash前缀找到目标在Term Dictionary的起止点,然后二分,直到命中,得到Posting List
优化思路
从Lucene4开始,为了实现范围查询、前缀、后缀等复杂的查询语句,以及减少内存使用,Lucene采用了FST(Finite State Transducer,直译为有限状态传感器)来存储Term Index。
FST和整个ES的分词和查询的数据结构,如下
FST的优点
占用内存小,只有HashMap10分之一左右,通过对词典中单词前缀和后缀的重复利用,压缩了存储空间
查询速度快,相当于HashMap,跟Map结构很相似,有查找,有迭代
FST的缺点
结构复杂、输入要求有序、更新不易
最右边是 invert index,也可以认为是Posting List,这是倒排表。这是一个int的数组,存储了所有符合某个Term的文档id,设计要求:Posting List是有序的,好处是方便压缩
Lucene在磁盘的情况
假设我们的es数据存储路径是:/data/es
那demo的绝对路径就是:
/data/es/data/nodes/0/indices/xxxxxx/0/index/xxx.dvd 可以在最下面这个目录,查看所有文件,索引文件、源数据文件等都在这里,一个index就是一个完整的Lucene的结构。
ES的索引思路
通过多级索引的方式,减小最前端索引占用的空间。PS:与操作系统防止页表太大,分为多级页表,想法类似。
将索引放入内存,尽可能减少磁盘随机读,提高索引查找效率
在索引的各个结构Term Index、Term Dictionary、Postintg List上,采用了压缩技巧,能够减少内存占用、一次磁盘IO能读入更多的数据,从而侧面减少磁盘随机读。
唠嗑广场
野生观察家就是我,观察2022-2023年的经济情况,遇到了一定的波折,那假设经济恢复,有什么野生指标吗?我拍脑袋想,大概有这几个吧。
1、恒大、碧桂园处理结果落地,房地产变成或者回到到正常行业,GDP占比降低。
2、大学生、年轻人的就业不再困难。